




The Internet of Things (IoT) and the advances in sensors have drastically increased the number of devices connected to the Internet. This has led to a great increase in real-time data available from sources such as industrial processes, networking traffic, social networks, bank data, etc.
Those data sources provide large volumes of data, generated continuously as data streams, potentially unbounded. Usually, it is not possible to store all the information generated from a data stream; it must be processed, analyzed, and then discarded. It is also important to do that processing in real-time, as the data stream could represent some evolving processes whose features change over time, and an output is required before all data is available.
Online clustering, also called Evolving Clustering (EC) or dynamic clustering, deals with this type of data. These algorithms create an initial grouping with a subset of the data. Afterward, that initial clustering is updated when new data is processed. It is necessary to reach a compromise between preserving the definition of the clusters that have already been learned and allowing its evolution when the underlying data structure changes. This is the stability-plasticity dilemma: how to remain adaptive (plastic) in response to significant input change and stable in response to irrelevant input. Too much plasticity will result in a substantial risk of the previous structure being destroyed by noise and/or outliers, whereas too much stability will impede adaptation to changes.
In the literature, this is often achieved by combining a new sample that has been assigned to a cluster with some type of representative of the cluster. This combination is weighted based on the number of samples which had previously fallen in it, but it does not take into account the order of arrival. When the sample number 1 million, for example, is assigned to a cluster, its weight in the definition of the cluster’s prototype will be the same as the weight of the first sample that fell on it.
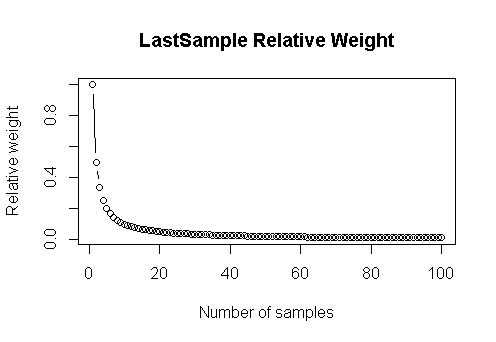
Image courtesy David Gonzalez Marquez
When the clusters evolve over time, the weight should depend on the order of arrival of the sample. As a general rule, the most recent data should carry more weight in defining the current partitions than older data. In fact, if there has been a large drift in the data source, the oldest samples may be irrelevant for the current definition of the clusters.
We propose a novel and simple strategy to evolve the clusters, based on an adjustable weighting scheme that enables the algorithms to “forget” old samples at a rate controlled by a single intuitive memory parameter. In this weighting scheme, we increase the weight of each new sample by a rate controlled by a single parameter (m):
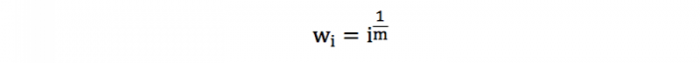
Using this weighting-scheme, the weight of the sample depends on its order of arrival but not on the total number of samples available. When a new sample arrives, it is assigned a higher weight than the previous sample; therefore, the relative importance of the older samples decreases, although they keep their weight constant. This avoids recalculating the weight of each sample when a new sample arrives, which could be an unacceptable burden for large data streams.
For higher values of the memory parameter, more weight is given to older samples, and for smaller values, more emphasis is made on the most recent samples. With no memory (m=0) all the samples are forgotten but the last one. With infinite memory (m=∞) all samples are remembered and they all have the same weight.
Using this weighting scheme, we can develop easily new prototype-based evolving clustering algorithms. We have demonstrated its potential showing how it can be used to build two evolving clustering algorithms, Evolving K-means and Evolving Gaussian Mixture models, just by making small modifications to their static counterparts (Published in an R-package https://github.com/DavidGMarquez/evolvingClusteringR).
Credit: David Gonzalez Marquez
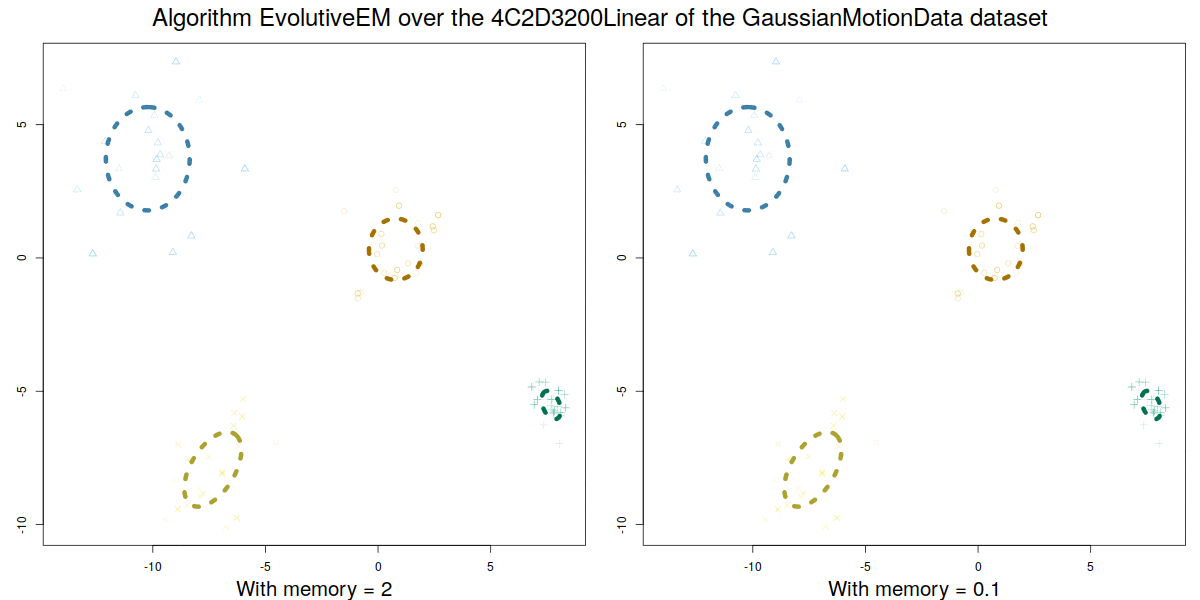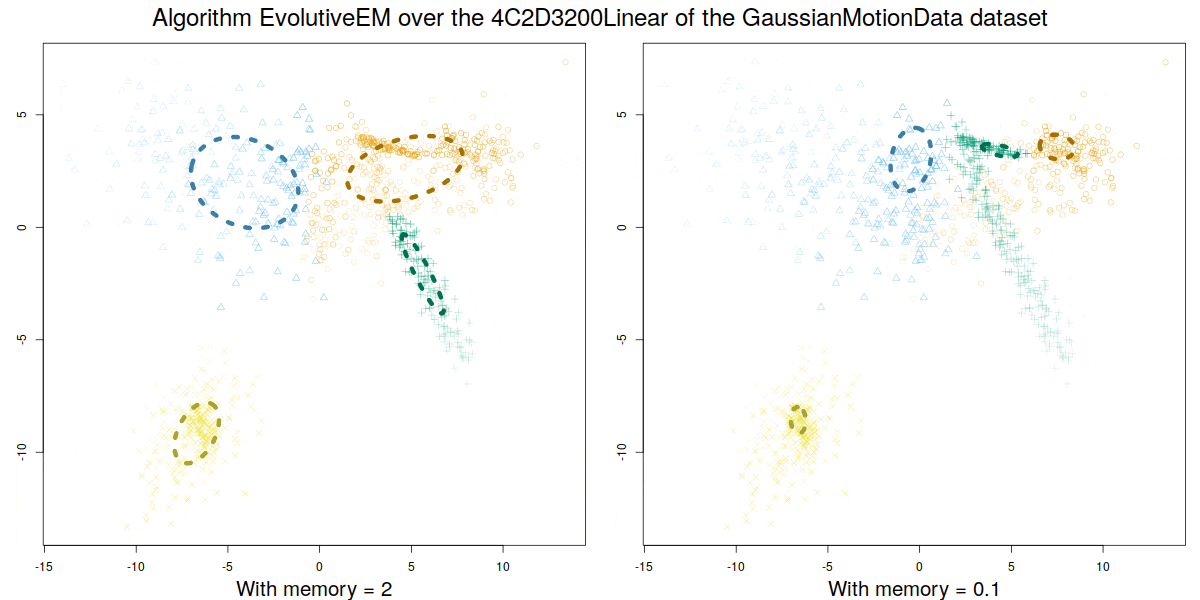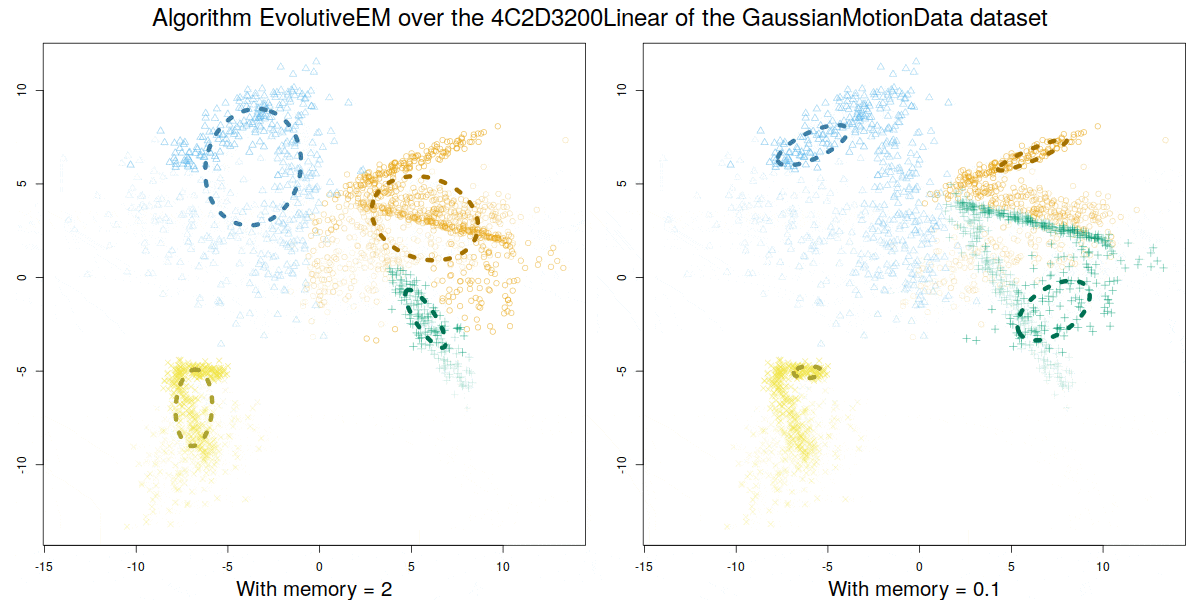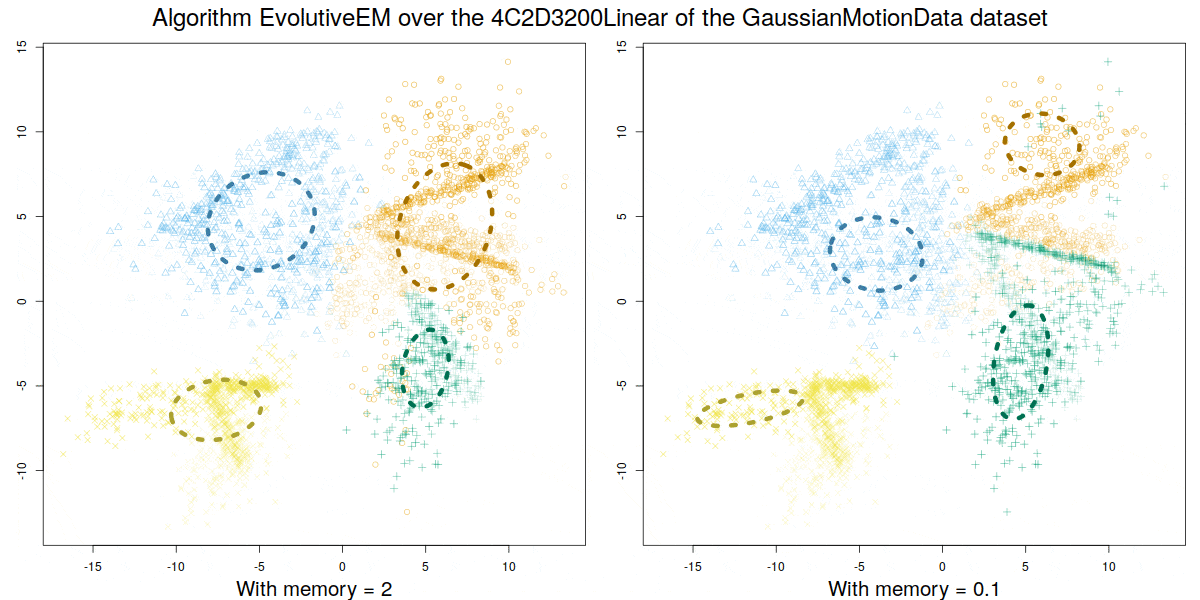
Credit: David Gonzalez Marquez
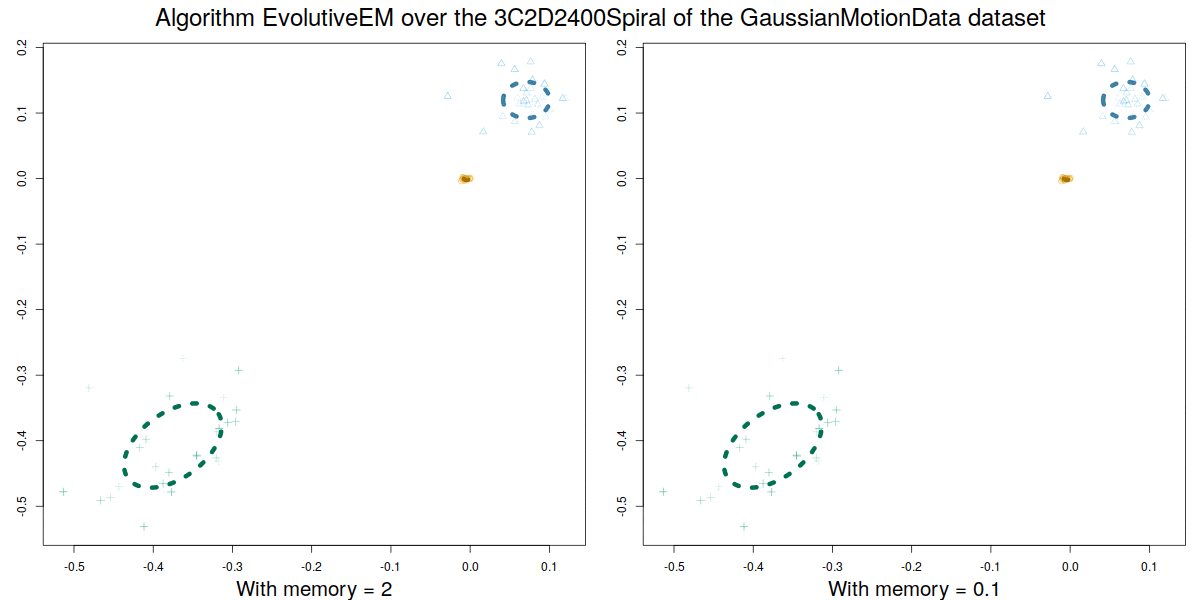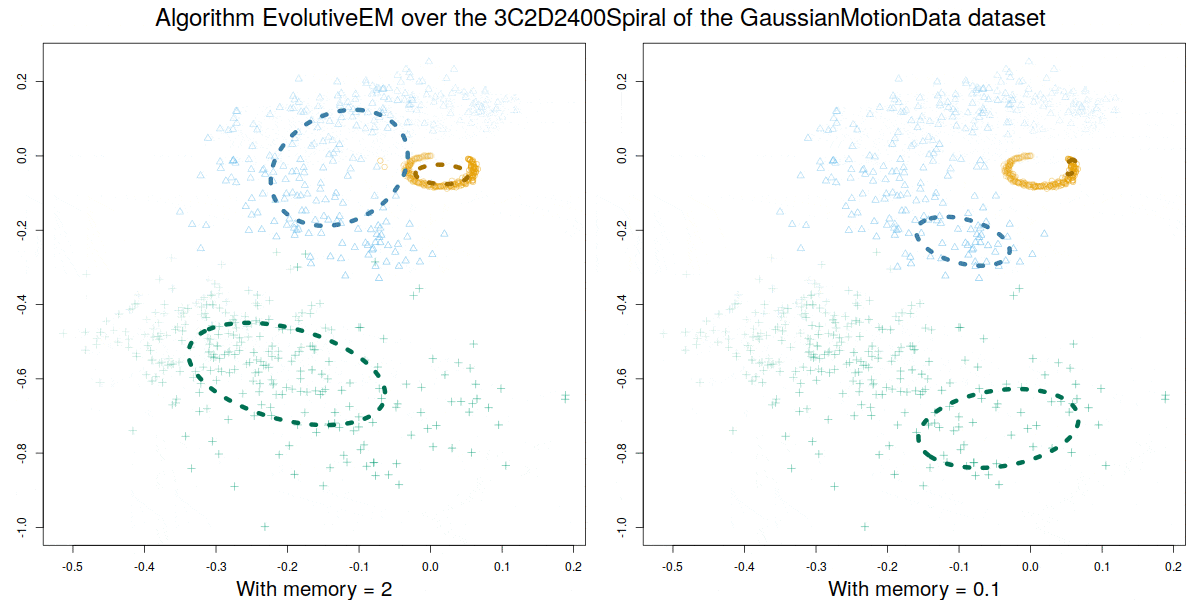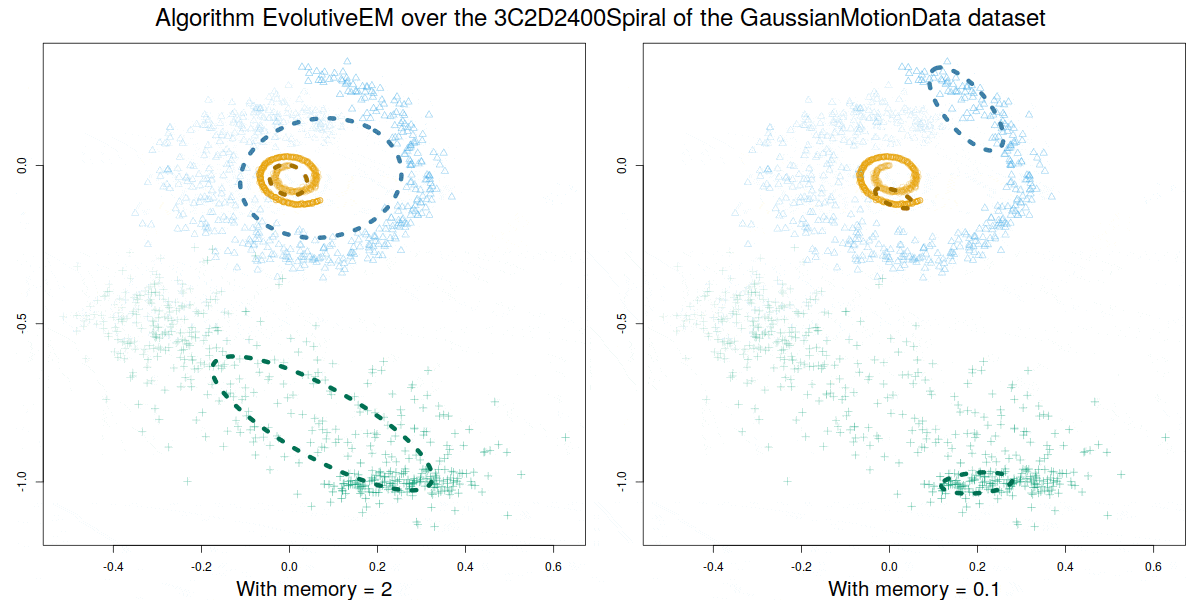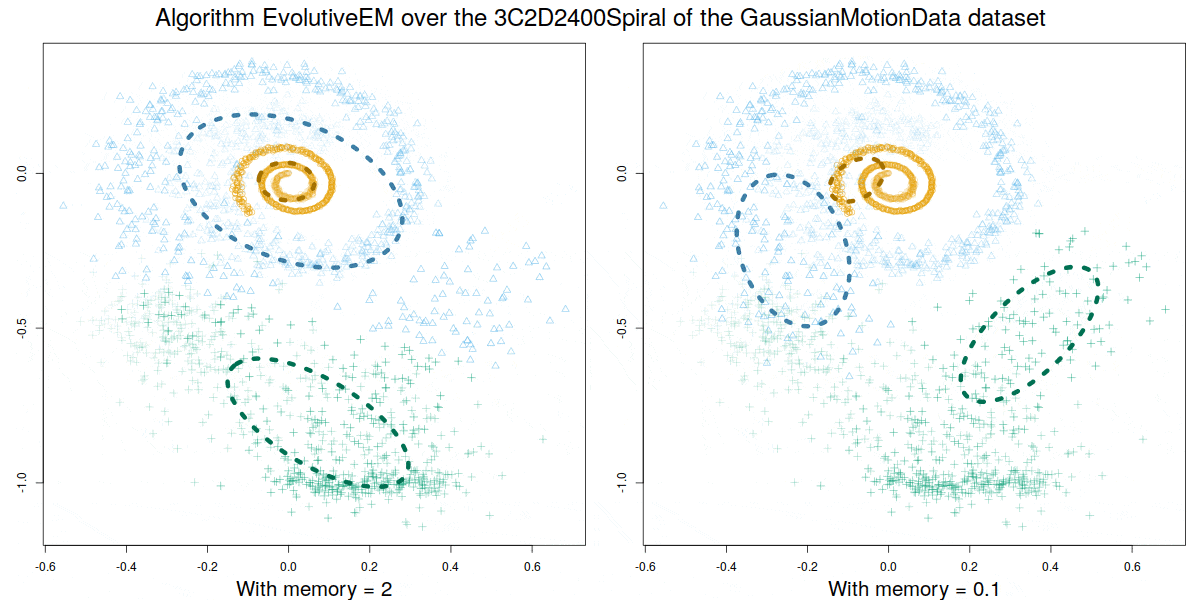
These algorithms were validated over a synthetic database GaussianMotionData (https://citius.usc.es/investigacion/datasets/gaussianmotiondata) where both abrupt and smooth changes occur, and over real data, demonstrating their capability to handle multiple concept drift situations.
These findings are described in the article entitled A novel and simple strategy for evolving prototype based clustering, recently published in the journal Pattern Recognition. This work was conducted by David G. Márquez from the University San Pablo CEU and the University of Santiago de Compostela, Abraham Otero from the University San Pablo CEU, and Paulo Félix and Constantino A. García from the University of Santiago de Compostela.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms