





Humans are bound to move inter-urban areas on a daily basis, and understanding human mobility is vital to explain the processes related to this human phenomenon [1]. Human mobility is an interdisciplinary topic with influence from multiple areas of knowledge [2], such as geography, physics, and social sciences. Better models to describe human mobility can support urban planning activities [3, 4, 5, 6], help forecast the spread of epidemics [7, 8, 9], and prevent catastrophic events [10].
Throughout decades, several laws were stated to describe the mobility phenomenon, such as the laws of migration [11] and the law of intervening opportunities [12], but just recently they were revealed not to be suitable to most mobility-related scenarios [13]. Consequently, we still lack an accurate model to understand the complexities behind this human behavior, especially with respect to the pendular movement in inter-urban areas.
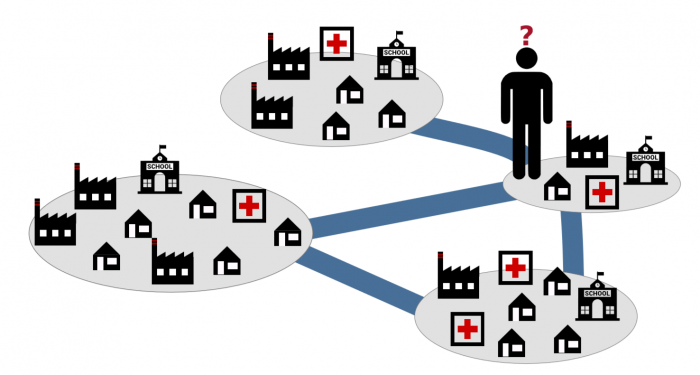
Figure 1: An illustration of the human-mobility problem concerning the citizens’ choice of where to work based on distance, job opportunities, housing prices, medical assistance, and other urban indicators — Image reproduced from Spadon, G. et al. [14] “Reconstructing commuters network using machine learning and urban indicators,” Scientific Reports 9(1), 11801, licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0).
Along these lines, we propose a novel approach to quantify the flow of people and reconstruct the network topology of human mobility through supervised machine learning algorithms of classification and regression. These algorithms adapt at each iteration to learn from the data, which improves the prediction ability of the model, making the results more accurate. Both classifiers and regressors are based on the classical machine learning paradigm, according to which the machine uses features to learn a model able to predict the labels (classes) in a two-stage process: training and testing [23].
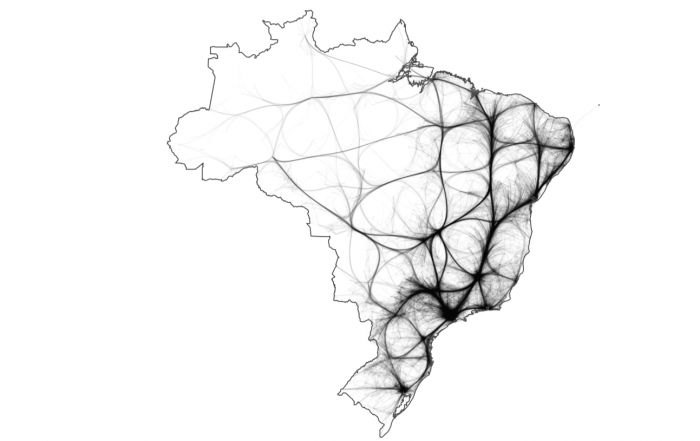
Figure 2: An illustration of the Brazilian commuters’ network. Notice that due to the high overlap of edges, we used an Edge Bundling technique [22] to enhance the visualization — Image reproduced from Spadon, G. et al. [14] “Reconstructing commuters network using machine learning and urban indicators,” Scientific Reports 9(1), 11801, licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0).
The model we propose, which relies on gradient-based machine learning algorithms, can predict the links of the commuter network with 90.4% of accuracy and weight these same links with 77.6% of the variance between the predicted and the observed flow of people between cities. Moreover, we use SHapley Additive exPlanations [24] (SHAP) values to interpret the results of the machine learning model so to quantify the importance of each feature in the prediction task. Through this technique, it was possible to identify which are the most important features to describe the phenomenon of human mobility. We notice that not only is distance critical in shaping human mobility, but also other variables such as GDP and unemployment rate play important roles in this phenomenon.
Acknowledgments
The authors would like to thank Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brazil (CAPES) – Finance Code 001; Fundaçõ de Amparo à Pesquisa do Estado de São Paulo (FAPESP), grants 2013/07375-0, 2014/253370, 2016/16987-7, 2016/17078-0, 2017/08376-0, and 2019/04461-9; Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq) grants 303694/20157, 404870/2016-3, 167967/2017-7, and 305580/2017-5; and Intel for their financial support.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms Game Designed To Innoculate People Against Fake News Help Increase Skepticism
Game Designed To Innoculate People Against Fake News Help Increase Skepticism