




Nucleic acids (a.k.a DNA and RNA) are composed out of monomer units called nucleotides. Nucleotides are the basic building blocks of DNA and RNA, two molecules essential for life as we know it. Molecules of both DNA and RNA serve as the genetic code that uniquely identifies every living organism. One can think of DNA and RNA as sets of instructions that guide the construction of proteins and the cellular organization of the body.
The genetic information in DNA and RNA is encoded in the form of sequences of nucleotide bases. Each nucleotide sequence encodes the instructions to create a particular protein that serves some function. In each cell of every living organism is a soup of nucleic acids that encode the genetic information for that organism.
Nucleotides also play an important role in metabolism. Nucleotides like adenosine and guanosine form the main body of molecules like ATP and GTP. The energy derived from such molecules drives virtually every biological process. Nucleotides also form the base of important enzymes and cofactors that figure into cellular respiration, like coenzyme-A, NADH, and, FADH.
Nucleotides: The Basics
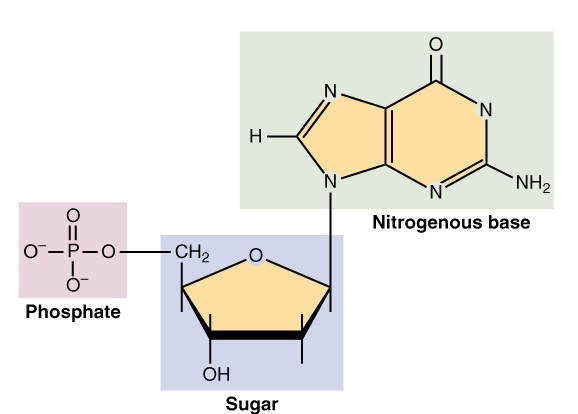
The general structure of a nucleotide. Credit: “DNA nucleotides” OpenStax via WikiCommons CC BY-SA 4.0. Image cropped
{kind=link}
Nucleotides are organic macromolecules that have 3 main chemical sub-units: a nitrogenous base, a 5-carbon sugar group, and a phosphate group. When all three are joined together, the molecule is called a nucleoside monophosphate. Adding more phosphate groups makes a nucleoside di- and tri-phosphate, and so on.
Nucleotides have nitrogenous bases of two kinds, purine or pyrimidine. In RNA, the 5-carbon sugar group is called ribose, and in DNA the 5-carbon sugar is deoxyribose. Nucleotides bond to form polynucleotide chains. These polynucleotide chains form by a dehydration reaction, in which the sugar in one nucleotide is bonded to the phosphate group of another and a water molecule is removed. These phosphodiester linkages are what form the sugar-phosphate backbone of strands of DNA and RNA. Assemblies of polynucleotide strands are called nucleic acids, DNA and RNA.
Nucleotides are extremely important because they serve as the fundamental bits of information in DNA, analogous to the binary 1 and 0 of a digital computer. If a nucleotide sequence in DNA is switched around or deleted, then the body will not construct the corresponding protein, which in many cases is fatal.
Functions Of Nucleotides
DNA
DNA (deoxyribonucleic acid) is the molecule that contains the basic genetic code of an organism. Molecules of DNA contain purine and pyrimidine nucleotide bases. The purine bases are adenine and guanine (A and G) while the pyrimidine bases are cytosine and thymine (C and T). Together, these nucleotide bases form the bulk of sequences of DNA. DNA sequences are normally represented as repeating chains of bases, like AACCGT or TGCGTAA.
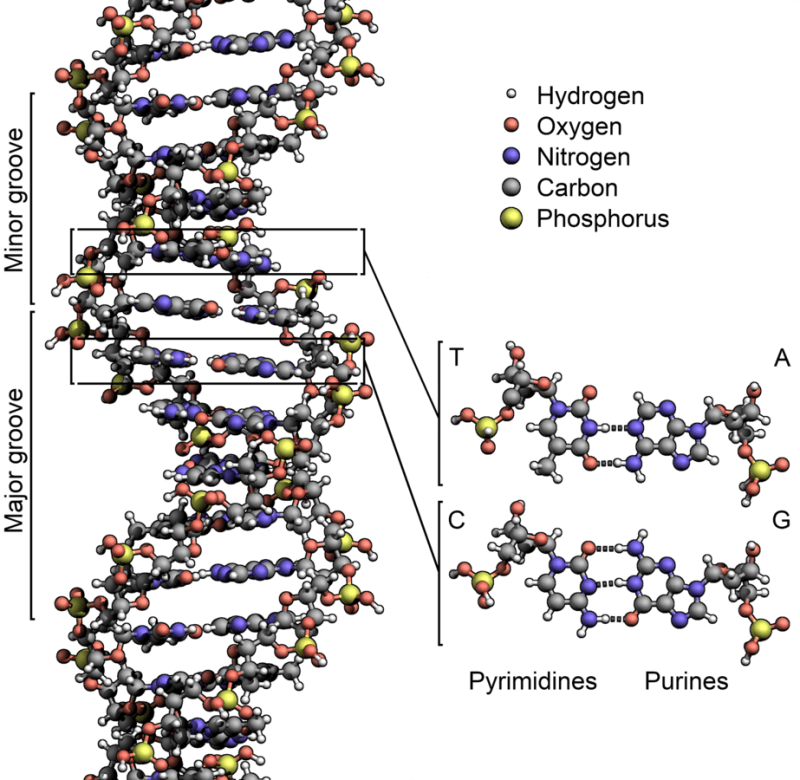
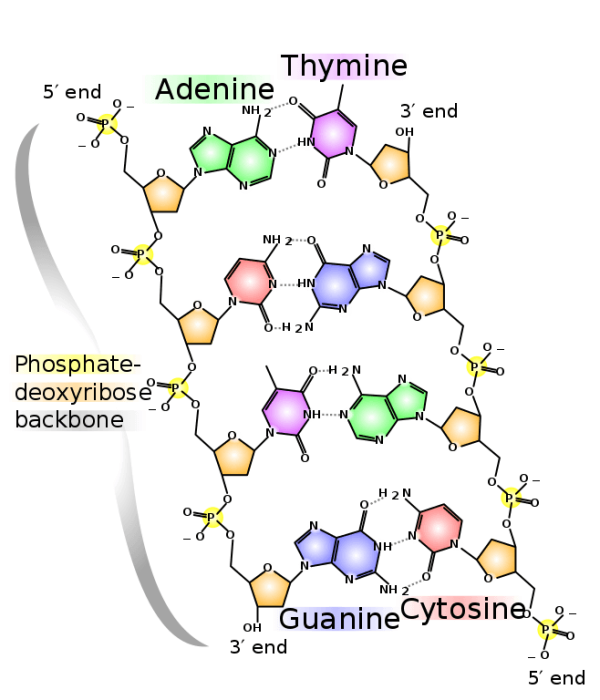
DNA molecules exist in a shape called a double helix. The double helix of DNA consists of a 2 phosphate strands each containing a linear sequence of bases. These phosphate strands wrap around each other like a twisted ladder, the rungs of which are formed by connecting nucleotide bases. In the helix, each base has a complementary pair that it couples with; adenine with thymine (A-T) and guanine with cytosine (C-G). The bases connect with each other via hydrogen bonds. This interconnecting structure is encapsulated in Chargaff’s law, an empirical generalization that states a ratio of certain bases in a molecule of DNA always holds; specifically, the amount of adenine matches the amount of thymine (A-T) and the amount of guanine matches the amount of cytosine (G-C).
The helical structure of DNA. Each nucleotide has a corresponding base that it forms base pairs with. Credit: WikiCommons CC0 1.0
DNA Synthesis
During cellular interphase and just before mitosis of meiosis, DNA is will replicate, creating identical copies of itself. Various enzymes and cofactors attach themselves to a double strand and will “unzip” the DNA strand by pulling apart the hydrogen bonds that hold the two strand together. Each of these two strands serve as the template for a new strand.
The main enzyme that assists in the synthesizing of new DNA is called DNA polymerase. DNA polymerase will attach itself to the newly split strands and begin creating a complementary strand of DNA. DNA synthesis works on the basis of corresponding nitrogenous bases. If one knows the sequence of the template strand, one can predict the composition of the complementary strand. Bases come in complementary pairs (A-T and G-C), so if the sequence of a template strand is AACCGGTT, we know that the complementary sequence is TTGGCCAA. Each nucleotide base has to match up with its complementary pair during DNA synthesis.
DNA is the molecule that contains the instructions that are executed by the cellular machinery of the body. DNA cannot do this on its own though and must rely on another kind of nucleic acid to transcribe and put those instructions into action.
RNA
RNA (ribonucleic acid) are the nucleic acids that take the code form DNA and use it to construct proteins. In other words, they are the biological machinery that extracts the genetic code from the DNA and executes the instructions. Like DNA, strands of RNA are made of polynucleotide chains. Unlike DNA, RNA molecules exist as single strands that loop back on themselves. RNA also uses a different set of nitrogenous bases than DNA. RNA contains 3 bases found in DNA, adenine, guanine, and cytosine. However, it lacks entirely thymine and instead uses a base called uracil (U) a different kind of pyrimidine.
Credit: “Artist’s impression of an RNA strand” UCL via Flickr CC BY-SA 2.0
Transcription
The primary function of RNA is to take extract the information in DNA and put that information to use in constructing proteins. This process is called transcription and is the first step in gene expression. During transcription, an enzyme called RNA polymerase attaches itself to a DNA strand and unwinds the strand, exposing the single strand to be transcribed. RNA polymerase will then begin to construct an RNA strand with a complementary sequence of nucleotides. The building of the complementary strand is similar to the action of DNA polymerase during DNA replication, excepts RNA polymerase uses a U base in place of the T base. So if the DNA strand has an A in some location, the complementary RNA strand will have a U in that spot, instead of a T.
Once the RNA strand has transcribed the relevant nucleotide sequence, it detaches from the DNA molecule. In bacteria, the newly synthesized RNA can act as messenger RNA (mRNA), but in eukaryotes, the RNA strand needs to be modified first. Eukaryotic pre-mRNA are capped at the ends and undergo splicing, where sequences of the pre-mRNA strand are cut out (introns) and the others are put back together (exons). Currently, the exact nature and reason for there being seemingly inert intron sequences in eukaryotic DNA is not well understood. It is believed that intron sequences may play some role in a single sequence coding for multiple proteins.
Translation
Each completed strand of mRNA contains the instructions for building some protein macromolecule. During the second part of gene expression, called translation, the information transcribed to the mRNA is extracted and the encoded protein is actually constructed. Essentially, the sequence of bases in mRNA gives instructions for cells to create sequences of amino acids, the basic building blocks of proteins.
The process of translation. Credit: “peptide synthesis” Boumphreyfr via WikiCommons CC BY-SA 3.0
{kind=link}
After transcription, the mRNA strand binds to ribosomes, cellular organelles where protein production takes place. Another type of nucleic acid, called transfer RNA (tRNA) binds to the mRNA at a certain location along the strand. tRNA strands bind according to their base pairs and bring along the amino acid specified by that specific RNA sequence. For example, the nucleotide sequence ‘AUG’ in RNA encodes for the amino acid methionine.
The ribosomes serve as a physical scaffolding for the construction of amino acid chains by tRNA, and as an enzyme that catalyzes the reaction that binds amino acids together. this process continues down the RNA strand, constructing a growing polypeptide chain. After the translation is complete, the constructed polypeptide chain just needs a few more modifications before it is ready to act as a full-fledged protein. Most proteins fold to a specific shape that allows for their functioning, and some must first be transferred to another place in the body before they can start doing work.
Cellular Metabolism
In addition to their ubiquity in genetics, nucleotides also serve as important molecules for cellular respiration. Each nucleotide base in DNA (A, C, G, and T), serves as the backbone for the energy-carrying molecules created during cellular respiration. Most abundant is ATP (adenosine triphosphate). ATP is the main product of cellular respiration and is the fundamental energy currency of the cell. The C, G, and T bases are capable of forming analogous triphosphate molecules CTP, GTP, and TTP. Each of these molecules has a high energy density and so are put to work providing energy to the parts of the body.
The same nucleotides are also present during the process of respiration as important cofactors and enzymes. Coenzyme-A, the molecule that donates the acetyl group required for the Krebs cycle, is formed with adenine, and the two enzymes that form the bulk of the electron transport chain, NADH and FADH, contain nucleotide substructures.
Related Posts
 Be Careful When Speaking About Lead Pollution: The Good, The Bad, And The Ugly!
Be Careful When Speaking About Lead Pollution: The Good, The Bad, And The Ugly! Temperature Has A Significant Influence On The Production Of SMP-Based Dissolved Organic Nitrogen (DON) During Biological Processes
Temperature Has A Significant Influence On The Production Of SMP-Based Dissolved Organic Nitrogen (DON) During Biological Processes Does The Arrow Of Time Apply To Quantum Systems?
Does The Arrow Of Time Apply To Quantum Systems? Labeled Periodic Table
Labeled Periodic Table A “Twist” In Wavefunction With Ultrafast Vortex Electron Beams
A “Twist” In Wavefunction With Ultrafast Vortex Electron Beams Chemical And Biological Characterization Spot The Faith Of Nanoparticles
Chemical And Biological Characterization Spot The Faith Of Nanoparticles