





Published by Tanmoy Chakraborty
IIIT Delhi, India
These findings are described in the article entitled Ensemble-based overlapping community detection using disjoint community structures, recently published in the journal Knowledge-Based Systems (Knowledge-Based Systems 163 (2019) 241-251). This work was conducted by Tanmoy Chakraborty from IIIT Delhi, Saptarshi Ghosh from IIT Kharagpur, and Noseong Park from George Mason University.
Most of the complex systems such as social networks (e.g., Facebook, Twitter), biological systems (e.g., protein-protein interactions) can be modeled by networks/graphs where nodes/vertices in a graph represent different objects/entities (users in social networks, proteins in biological systems) and edges/links between nodes represent relationships between objects (friendships in social networks, proteins interacting during the metabolic process within a cell). Due to the availability of large data, researchers working on difference disciplines (such as computer science, physics, biology, and mathematics) have started representing the overall complex system using graphs.
One of the important problems in graph analysis is to detect densely connected nodes, aka “communities” or “clusters”. What is the definition of a community structure is still an “ill-posed problem” – although it is roughly defined as the groups of nodes densely connected internally and sparsely connected externally, several metrics such as modularity, conductance, cut ratio, and permanence have been proposed to define a community structure (Readers are encouraged to read “Metrics for community analysis: A survey,” by Chakraborty et al., ACM Computing Surveys, 2017 to know all possible definitions of a community).
There are two types of communities in graphs – disjoint, where a node can belong to only one community, and overlapping, where a node can be a part of more than one community (see Fig 1). While disjoint community is a more theoretical concept of network partition, overlapping community is more natural in real world, e.g., in social networks, a user is usually a part of many communities (communities of his/her high school friends, college friends, and colleagues, etc.). However, the complexity of the problem of community detection will exponentially increase when we go from disjoint to overlapping community detection due to the exponential number of possible ways to assign nodes into groups.
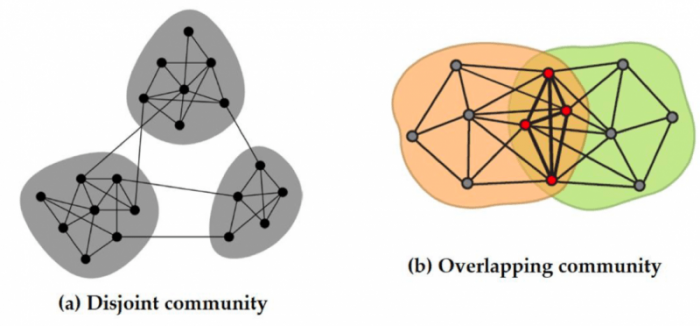
Fig 1: A schematic example disjoint and overlapping community structures. Image republished with permission from Elsevier from https://doi.org/10.1016/j.knosys.2018.08.033.
There has been a plethora of research in detecting disjoint communities. Readers are encouraged to read “Community detection in graphs,” by Santo Fortunato, Physics Reviews 2010, to know more about disjoint community detection methods. Compared to this, the literature on overlapping community detection has been relatively less (read “Overlapping community detection in networks: the state-of-the-art and comparative study,” by Xie et al., ACM Computing Surveys 2011) till 2014. In recent years, attempts have been made by various interdisciplinary research communities to develop algorithms for overlapping community detection. As a result, it has become immensely difficulty for beginners (who are unfamiliar with the literature on community detection) to pick and apply a specific (and usually the best) community detection algorithm from the ocean of algorithms.
Through a series of studies, we started believing that overlapping community detection can be solved using disjoint community detection methods. We empirically observed that in the case of most of the real networks, nodes laying at the border of the disjoint communities are responsible for forming the overlapping part of the community structure. So if we run an accurate disjoint community detection algorithm, identify peripheral nodes, and assign them to appropriate communities, we may be able to get the final overlapping community structure.
In 2015, I made the first attempt to prove this hypothesis empirically, which resulted in the following publication: “Leveraging disjoint communities for detecting overlapping community structure,” T. Chakraborty, Journal of Statistical Mechanics: Theory and Experiment (JSTAT), 2015. In this paper, I used a metric, called “permanence,” which was proposed by us earlier for disjoint community detection (“On the permanence of vertices in network communities,” Chakraborty et al. ACM SIGKDD 2014), to identify such potential peripheral nodes which are responsible to form the overlapping community structure.
In 2018, we made a second attempt to prove our hypothesis again, which resulted in the following publication: “Ensemble-based Overlapping Community Detection using Disjoint Community Structures,” Chakraborty et al., Knowledge-Based Systems, 2019. In this work, we hypothesized that, instead of designing yet another overlapping clustering method, an alternative way could be to leverage the community structures obtained from various heuristic-based disjoint community detection methods on a given network and discover the overlapping regions. We are the first to propose an ensemble algorithm, called EnCoD, which systematically materializes the hypothesis mentioned above.
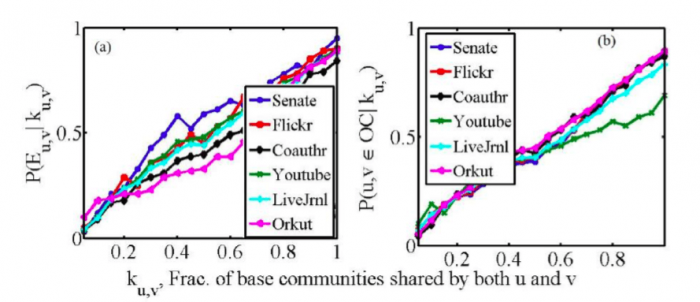
Fig 2: Conditional probability P (in y-axis) of (a) existence of an edge between two vertices, and (b) common overlapping community (OC) membership of two vertices in the ground-truth community structure of six real networks (Senate, Flickr, Coauthorship, Youtube, LiveJournal, Orkut), given the fraction of the base disjoint communities that both the vertices share. We conclude that the more the vertices share common base disjoint communities, the more the chance that they are connected in the graph and belong to the same overlapping community. Image republished with permission from Elsevier from https://doi.org/10.1016/j.knosys.2018.08.033.
The backbone of EnCoD stands on an interesting observation drawn from multiple real-world network structures as follows: the more a pair of nodes co-occur together in the same “base disjoint communities” (i.e., communities obtained from different disjoint community detection algorithms), the more the chance that they will be connected via an edge in the original network and they share same overlapping region. We ran several well-known disjoint community detection algorithms (we call them “base disjoint community detection methods”) and detected disjoint community structures (we call them “base community structures”). EnCoD uses the information of the community memberships of a vertex as features and iteratively learns the major dimensions of features which would lead to the densely connected network.
In particular, since the base disjoint community detection methods are built on different heuristic methods, the base community structures that we obtain from a particular network would be significantly different. Therefore, EnCoD iteratively keeps on exploring the important dimensions from the vector to generate the network structure. EnCoD further uses two novel observations from the real-world networks: (i) nodes are densely connected in the overlapping regions, compared to the non-overlapping regions, and (ii) nodes belonging to the same communities are highly similar in terms of their feature vectors.
To evaluate the performance of EnCoD, six large real-world networks were considered whose ground-truth overlapping community structures (the actual community structure that the algorithm should be able to detect) are known to us, along with many synthetically-generated networks. EnCoD was compared against several state-of-the-art overlapping community detection methods. We observed that:
- The performance of EnCoD does not vary much with the performance of the base algorithms; however, care should be taken to detect more diverse base algorithms.
- The performance of EnCoD remains consistent after inclusion of a certain number of base algorithms.
In general, EnCoD turns out to be the better overlapping community detection method than other baseline methods. - The idea behind the design of EnCoD can also be used when vertices are associated with other types of features.
We believe that this work will enable others to realize that there may not be any further need to develop yet another overlapping community detection method. We also believe that the paradigm of ensemble learning is new in the context of community detection, which needs further studies both theoretically and empirically.
The paper is available at https://www.sciencedirect.com/science/article/pii/S0950705118304258
The preprint of the paper is available at https://arxiv.org/abs/1808.06200.
More details on the related publications can be available at https://sites.google.com/site/tanmoychakra88/ and http://lcs2.iiitd.edu.in.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms