





Financial inclusion is a globally recognized problem. Around two billion people do not have a basic bank account, and, in some countries, large parts of the population do not have access to useful and affordable financial products and services such as checking accounts, saving instruments, and loans. The World Bank, the G20, and more than 55 countries have committed to the advancement of financial inclusion worldwide through initiatives such as the Financial Inclusion Global Initiative (FIGI) and digital finance technology, or fintech. At the same time, there is a global adoption of cell phones, particularly in developing countries.
As people use their phones, behavioral data is produced and, in this study, we investigated the potential use of this mobile phone data for credit scoring. Credit scoring is one of the oldest applications of analytics where the goal is to decide how likely potential borrowers are to pay back the money they borrow. This is typically done using the customer’s bank data, such as their income and repayment history. If this data is unavailable, the borrower will usually have a very hard time getting access to funds.
Figure 1: Intensity, diversity, and timing of individual calling behavior. Figure courtesy María Óskarsdóttir.
In this study, we show that in the absence of traditional data, mobile phone data can be used as an alternative data source for credit scoring. We used a combination of bank and mobile phone data to predict the credit-worthiness of credit card applicants. From the bank data, we obtained variables that are typically used in credit scoring, including sociodemographic variables. The mobile phone data was aggregated on the customer level to obtain variables that represent calling behavior including diversity, intensity, and timing of phone calls – both made and received – by each customer. We also used mobile phone data to construct social networks based on the exchange of phone calls between people.
Using these networks, we could see the characteristics of people that are in contact with the potential borrowers. In particular, we could see whether they had late payments of their own. These variables that represent the properties of neighbors are called link-based variables.
Finally, two techniques that simulate the spread of influence in a network were applied. These techniques are similar to the algorithm Google uses to rank webpages. The resulting scores represent how exposed the customers are to bad – or default – influences in the network. The scores were then also used as variables. In total, there are four groups of variables: bank and sociodemographics (SD), calling behavior (CB), link-based (LB), and influence scores (PR & SPA). All these variables were combined in a predictive model for credit scoring with a focus on assessing the importance of variables from each group.
Overall, the calling behavior variables were most predictive, as can be seen in the two figures below. The figures show the twenty most important variables of the credit scoring model in terms of statistical and economic performance. The variables are colored depending on which group they belong to. The SD variables are orange, the CB are green, the LB are yellow, and the influence scores are blue.
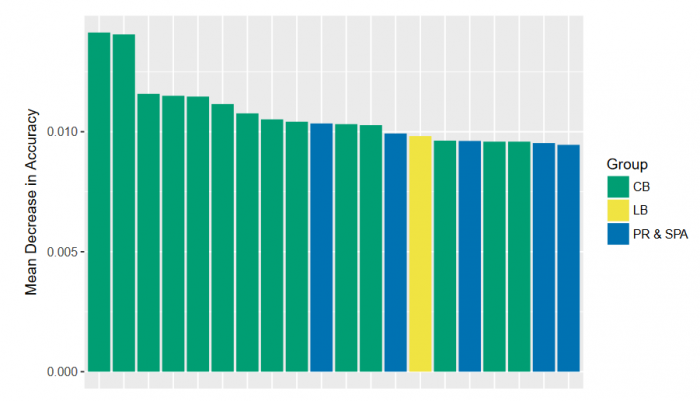
Figure 2: Statistical model performance. Figure courtesy María Óskarsdóttir.
The plot in figure 2 shows the statistical performance of the variables. In this plot, there are no socio-demographic variables, and calling behavior variables are most prominent. There is a similar trend in the economic performance of the variables, as can be seen in the plot in figure 3. Again, calling behavior variables are most common, but there are also a few sociodemographic variables. In both cases, link-based variables and influence scores are less important. The results of our study show that combining mobile phone data with traditional data in credit scoring models significantly increases their performance and that mobile phone data can even be used without traditional data to produce equally good credit scores.
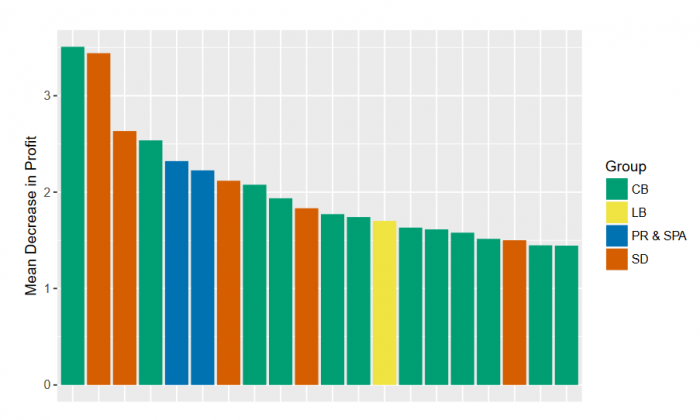
Figure 3: Economic model performance. Figure courtesy María Óskarsdóttir.
Furthermore, calling behavior variables are more predictive than both link-based and influence variables. This means that WHO the customer is in contact with is not important, only the diversity, intensity, and timing of the customer’s own calling behavior. This is an interesting result since it indicates that people’s phone usage can be used as the sole data source when deciding whether they should be granted a loan. Borrowers with little or no credit history, such as young borrowers or people in developing countries, are not expected to have a credit history, but they do have mobile phone records. The insights obtained from our study could thus facilitate access to these borrowers and potentially help increase the financial wellbeing of numerous individuals worldwide.
These findings are described in the article entitled The value of big data for credit scoring: Enhancing financial inclusion using mobile phone data and social network analytics, recently published in the journal Applied Soft Computing. This research was conducted by María Óskarsdóttir, Cristián Bravo, Carlos Sarraute, Jan Vanthienen and Bart Baesens.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms