





Published by Hongyu Liu
State Key Laboratory of Software Development Environment, Beijing, 100191, China
These findings are described in the article entitled CNN and RNN based payload classification methods for attack detection, recently published in the journal Knowledge-Based Systems (Knowledge-Based Systems 163 (2019) 332-341). This work was conducted by Hongyu Liu, Bo Lang, and Ming Liu from the State Key Laboratory of Software Development Environment, and Hanbing Yan from the National Computer Network Emergency Response Technical Team/Coordination Center of China.
Motivations
Why use deep learning methods to detect malicious traffic? Deep learning models, especially Convolutional Neutron Networks (CNNs) have achieved remarkable results in the field of image classification, so we thought of applying the CNN method to malicious traffic detection.
One of the most appealing of CNN is that it does not depend on artificial features. The traditional machine learning method generally adopts the mode of “feature extraction + model fitting.” There is a general saying that “the upper limit of the method depends on the quality of features, the model training is only to approximate the upper limit infinitely.” The artificial features always have omissions, especially for latent variables. As a result, the quality of features becomes a bottleneck of traditional machine learning.

Figure 1: Features are abstract of data. Feature extraction is regarded as a mapping from date space to feature space. Good features can retain important characteristics of data. The samples are distinguishable in feature space. Bad features can`t describe data comprehensively, which may lead to samples that are indistinguishable in the feature space. Image republished with permission from Elsevier from https://doi.org/10.1016/j.knosys.2018.08.036.
Essentially, the malicious traffic detection problem is a classification problem. Due to its malicious intention, malicious traffic and normal traffic are different in content. For example, DDOS and scan traffic packets have a lot of padding. And C&C traffic packets have control commands. These contents are not common in normal traffic. Finding and highlighting these differences is the key to detection, and CNN can detect these differences. In addition, deep learning requires a large amount of training data, and the traffic data is very abundant, making it feasible to use CNN to detect malicious traffic.
Experimental methods
Compared with traditional machine learning methods, deep learning models are more complex and have more parameters. Therefore, model optimization is an arduous task in experiments. Our main experiment is conducted on the DARPA1998 dataset, which contains raw traffic data as well as data labels. It is noted that the labels are labeled on session, not packet. So we have to label every packet according to session information (session quintuple: source IP, source port, destination IP, destination port, protocol type). First, extract the corresponding traffic packet according to the IP and port (we used Wireshark), and then convert each byte in the traffic packet to feature vectors via ASCII code.
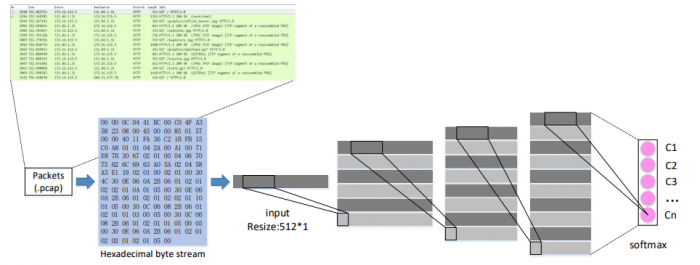
Figure 2: Experiment steps. Step 1: dataset sorting. Choose samples with different labels to constitute dataset, making a balance among different classes. Step 2: embedding. Transform every packet into a vector and resize. Step 3:, classification. Image republished with permission from Elsevier from https://doi.org/10.1016/j.knosys.2018.08.036.
In order to design a CNN structure suitable for traffic data, we also consider the similarities and differences between traffic flow and image.
The similarities:
- They are both inner-area related, considering an isolated point is meaningless.
- They are both data-redundancy. Except for a small part has a great influence on the classification, the rest is irrelevant.
The differences:
- The traffic data is one-dimensional, and the image is two-dimensional.
- The traffic is artificial, and the image is completely natural.
We have considered folding the traffic into a two-dimensional vector as input, but it will destroy the original structure of the traffic and produce redundant information. Our initial network was based on VGG-16. The initial network converged slowly and had serious over-fitting problems. It is necessary to optimize the network. Adjusting network structure needs to clarify the effect of each layer. The full connection layer will improve the classification effect but will lead to over-fitting, so we gradually removed the fully-connected layer. Batch Normalization (BN) can speed up convergence, and we added BN layers into the network.
Adjusting network structure is very significant for the overall effect. Adjusting hyperparameter is also an important step. Taking the learning rate as an example, we judged it according to the intermediate result during the training process. When the loss increases, the network is divergent and we reduce the learning rate. When the loss decreases slowly, the network may get stuck into local optimum and we increase the learning rate.
Conclusions
CNN is an effective general framework, but different structures need to be constructed for different problems. CNN is directly oriented to data and does not depend on artificial features. For traffic data, which is not intuitive, CNN can find its hidden mode. In other words, traffic is a kind of data which is suitable for CNN. CNN is a black box and may require a lot of trials to find an optimal solution. However, we can reduce the number of attempts dramatically through a clear understanding of CNN components and hyperparameters.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms