





The field of artificial intelligence has grown by leaps and bounds over the past couple decades advance, and now an AI called AlphaZero has taught itself to play chess with a superhuman level of knowledge in just a few hours. AlphaZero is a game-playing AI program derived from DeepMind’s AlphaGo. AlphaGo made headlines last year when it beat the world’s best Go players. In just four hours AlphaZero went from having absolutely no knowledge of the game to becoming the top-ranked chess playing program in the world.
Mastering Chess
Computer programs have been sophisticated enough to beat the best human chess players since at least May 1997 when IBM’s Deep Blue supercomputer defeated world chess champion, Garry Kasparov. However, Deep Blue was programmed with some inherent knowledge of chess, to begin with. It required human input to give it a knowledge of chess’ framework, like moves and strategies, and a system of algorithms to support that knowledge. By contrast, DeepMind’s AlphaZero employs machine learning. This means that once provided with the basic rules of chess the program is able to work out the optimal strategies by itself with no input from human agents.
“It’s a remarkable achievement, even if we should have expected it after AlphaGo,” says Garry Kasparov about AlphaZero. “We have always assumed that chess required too much empirical knowledge for a machine to play so well from scratch, with no human knowledge added at all.”
The researchers at DeepMind took AlphaGo’s basic framework and generalized it to create a system capable of learning other games in addition to Go. AlphaZero was then pitted against the most sophisticated chess playing program in the world, Stockfish 8. AlphaZero and Stockfish 8 played 100 rounds and AlphaZero was able to win or draw every single one of them. It didn’t lose a single round.
Demis Hassbis, the founder of DeepMind and himself a chess prodigy who mastered the game at only 13 years old, said that the remarkable thing about AlphaZero is that it employs a more human-like approach to discerning the optimal next move. AlphaZero is capable of processing almost 80,000 possible chess positions every second and it searches for the best move in a manner similar to humans.
Moving Beyond Chess
AlphaZero has also achieved astonishing proficiency with a Japanese board game called Shogi and Go, defeating a world champion of each game, and likewise starting from no knowledge accept the basic rules of the game.
AlphaZero was also put up against its sibling program AlphaGo. AlphaZero fared less well against AlphaGo than it did Stockfish 8, managing to win only 60 games and losing 40 rounds. Yet this is still quite impressive, as Go is a significantly more complex and computationally demanding game than chess is.
As for how the game fared in Shogi, it was able to achieve victory against an AI program dubbed Elmo after only two hours of training. AlphaZero was able to win 90 rounds, losing only eight and drawing two.
Machine Learning And Neural Networks
AlphaZero is able to learn how to play chess by employing machine learning within a neural network. A neural network or artificial neural network (ANN) is a model of computation that is based upon the neural networks found within brains. Brains have neural networks that consist of a series of neurons and synapses, these neurons and synapses form together in specific ways to create neural pathways, and the neural pathways can be reinforced by repeated use.
Likewise, an artificial neural network has a series of nodes, connected together by dependencies in a mathematical model. Every node in an ANN represents a simple mathematical operation along with specific parameters, and the output from one node can be adjusted by the next node. Artificial networks consist of an input layer, an output layer, and any number of hidden layers in the middle. Data is put into the system in the input layer, goes through a number of transformations via mathematical processes in the hidden layers, and then is output in the output layer.
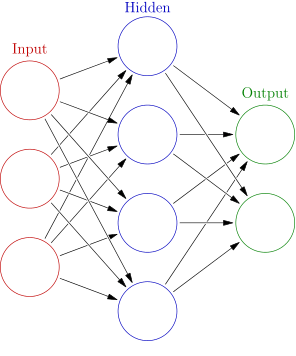
An artificial neural network consists of an input layer, any number of hidden layers, and an output layer. Photo: “Colored neural network” by Glosser.ca via Wikimedia Commons, CC-BY-SA 3.0
{kind=link}
Machine learning refers to the ability to learn from an association and improve the experience, to discover how to carry out a task without being explicitly programmed to do so. There are various methods of machine learning that AI researchers can employ. Supervised learning, unsupervised learning, and reinforcement learning are all methods of machine learning.
Supervised machine learning algorithms are given currently existing data and then they learn to generalize from that data. They analyze what is known as a training data set, search for patterns and functions within the data, and then make predictions regarding what the output value should be. Unsupervised machine learning systems, by contrast, are employed to derive a function from data that has not been labeled or classified. Unsupervised learning systems are able to infer functions from unlabeled data by exploring possible relationships between the data-points and drawing inferences from the data sets.
Reinforcement learning refers to systems that are reinforced by interacting with their environment. When the system takes an action, it can potentially discover a reward or produce an error. Essentially, this allows for trial and error learning, in which the system is rewarded for taking the correct actions. The system wants to maximize its performance, and thus its rewards, and by repeating actions that permit rewards (combined with exploring and learning about its environment) it can learn the optimal way to navigate a scenario.
AlphaZero utilized a unique form of unsupervised reinforcement learning, which effectively allowed the program to teach itself. AlphaZero basically played a series of games against itself, and as its simulated games played out the neural network within was updated and tweaked so that it could predict moves and the winner. DeepMind then re-combines the new neural network with a sophisticated search algorithm, to increase the knowledge of the network. The process then starts anew. Every time the process repeats AlphaZero becomes a little bit more knowledgeable about the game and the quality of its simulated games also increases. This process can happen very fast and sees exponential returns, so within only a few hours it can go from having no knowledge to being a master-level player.
Looking Forward

Demis Hassabis (left), co-founder of DeepMind about AlphaGo. Photo: By PhOtOnQuAnTiQuE from Earth France – PhotonQ-Demis Hassabis on Artificial Playful Intelligence, CC BY-SA 2.0, https://commons.wikimedia.org/w/index.php?curid=59031104
The results of the AlphaZero experiment are extremely impressive, and the technology developed to create AlphaZero has a wide variety of possible applications. However, it is important to keep in mind that AlphaZero is still carrying out fairly discrete tasks and that we’re still a long way off from any form of generalized artificial intelligence. That said, Demis Hassabis is already thinking about the applications for this technology beyond playing games.
Hassabis has suggested that with more refining of the technology, the program could have a range of applications in the sciences. For instance, it could be used to engineer new materials and create new types of drugs. While designing drugs and materials are fairly different problems to playing Chess or Go, the algorithms that AlphaZero employs have proven themselves to be more robust than most people expected. It is conceivable, with the right research and refinement, that the underlying structure of AlphaZero could take on complicated tasks like the designing of medical drugs.
In the meantime, DeepMind has successfully produced a program capable of learning multiple types of games in only a few hours, which is enough of an achievement to stand proud.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms