





Mapping of human knowledge has an ancient lineage. Thus, the Porphyrian tree (which was based on a single corpus, i.e., Aristotle’s works–specifically the categories) was manually put together by Porphyry of Tyre around 265 AD. Modern knowledge cartographers (i.e., scientometricians) use a variety of computational tools and techniques to help delineate and navigate the underlying conceptual structures, linkages, and impact of individual/group contributions across the exploding knowledge corpus. Geological cartography is informed by the underlying tectonic processes.
Likewise, knowledge cartography ought to be informed by the processes underlying the individual/group creation of human knowledge. Borrowing from the world of complexity sciences, this paper (Knowledge as a Complex Adaptive System-KaaCAS) describes human knowledge dynamics based on the theory of Complex Adaptive Systems (CAS) as first proposed by late Prof. John Holland.
The basic theory is fairly straightforward. As Prof. Holland describes it, CAS’s “are systems that have a large number of components, often called agents that interact and adapt or learn.” Holland then proposed a two-tiered system as shown in Fig. 1a below. The lower α-tier follows a fast-dynamic and is engaged in the flow of resources between diverse agents (in our case, human knowledge agents); while the upper β-tier follows a slow-dynamic that captures knowledge artifacts and aggregates from these which are then emitted system-wide as stigmergic signals that help humans organize and scale. Examples of these might be citation-indexes, page-ranks, funding, etc.
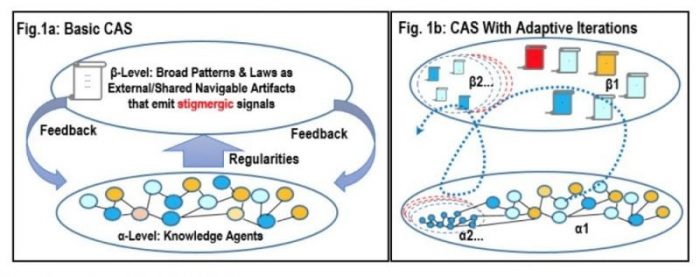
Figure 1. Republished with permission from Wiley from: https://doi.org/10.1002/cplx.21799
Given the abstract nature and spread of human knowledge, it may be observed that knowledge has a dynamic hierarchically-heterarchic structure as shown in Figs 2.a-f below. Concretes are far more numerous than abstractions; this implies that domain-specific human knowledge (Fig. 2b) has a conical/hierarchical shape. Induction flows along an upward arch, while deduction along a downward arch. This informs the on-going educational debate as to the proper division-of-labor between humans and machines: induction (that favors human faculties) versus deduction (that favors the machine) ought to be the proper role demarcation.
The rate of change is more pronounced along the lower rungs as compared to the higher, more abstract levels (Fig. 2a). Reverse-salients (Fig. 2c) are lagging knowledge fronts (the known-unknowns) that occur because of differentials in growth spurts across domains that are close enough to make sense if conceptual barriers didn’t exist. When they eventually gap-close, it ripples across the knowledge fabric both radially (i.e., hierarchically and denoted as |H) as well as tangentially (i.e., heterarchically and denoted as |h).
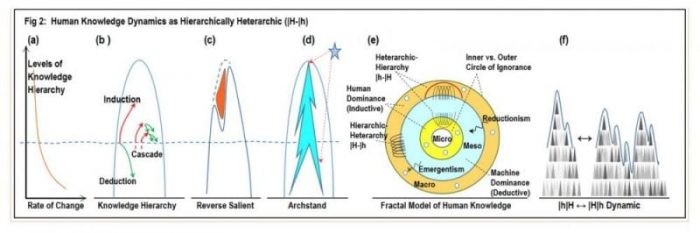
Figure 2. Republished with permission from Wiley from: https://doi.org/10.1002/cplx.21799
Yet another source of knowledge dynamics is the archstand—an integrated external perspective such as the Non-Euclidean framework that gave rise to the Theory of Relativity. When stand-alone domains are organized using domain kinship metrics, one may expect these conics to exhibit a self-similar fish-scale (hierarchically-heterarchic) fractal structure (Fig. 2e). Humans are at the mesoscale. Unknowns from the macro-world dominate the outer realms; unknowns from the micro dominate the inner regions. Knowledge is sandwiched between these two outer and inner circles-of-ignorance that are expanding and contracting respectively.
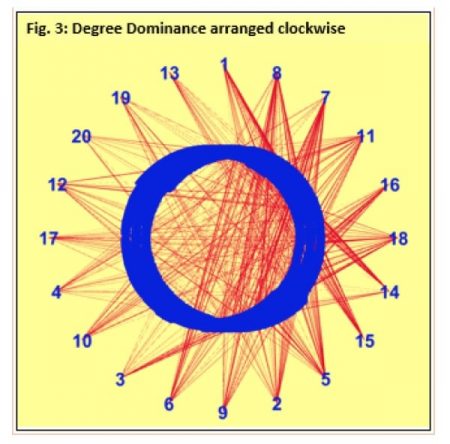
Figure 3. Republished with permission from Wiley from: https://doi.org/10.1002/cplx.21799
Between hierarchies and heterarchies, hierarchies exhibit relatively stable vertical linkages; whereas heterarchies exhibit dynamic linkages that are conceptual mashups in the making. At finer grains, hierarchies may contain heterarchies and vice-versa, and switch dominance across time (Fig. 2f).
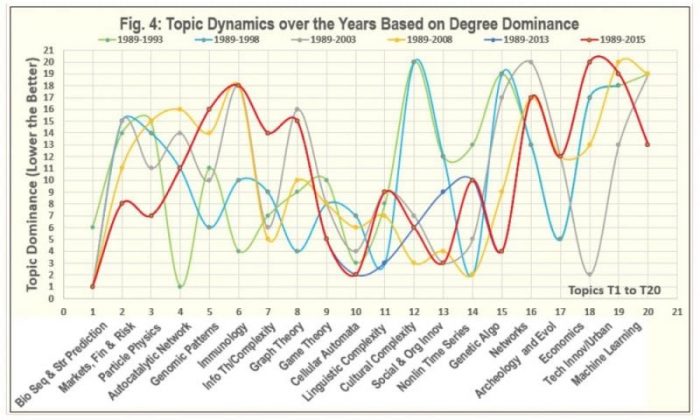
Figure 4. Republished with permission from Wiley from: https://doi.org/10.1002/cplx.21799
With the above KACAS framework in place, one may then consider how best to validate the theory. About 1400 complexity science papers published at the Santa Fe Institute (SFI) were analyzed using the topic-modeling method of LDA (Latent Dirichlet Allocation). Gephi was used to both navigate and visualize underlying network dynamics of the corpus as it evolved over the years between 1989-2014. Two such graphs are as shown in Fig. 3-4 below. For example, T15: Genetic Algorithm has consistently gained in rank across all the periods and was the lead advancer overall. In contrast, T18: Economics lost rank to every other topic during this period.
In conclusion, the above work is but a small step. In truth, to assemble something that resembles Fig 2e will require an effort similar to the human genome project. This is merely a modest beginning.
The study, Mapping complexity/Human knowledge as a complex adaptive system was recently published in the journal Complexity.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms