





The current hardware for training neural networks, the backbone of modern artificial intelligence, is the graphics processing unit (GPU). As its name suggests, the GPU was originally designed for rendering images at high speeds; the realization that it could be used for training neural networks was serendipitous.
When training neural networks on GPUs, one is simulating the algorithmic mechanisms in software, and this gives rise to various limitations that are not present in biological neural systems. For example, in GPUs, memory storage and computation happen in separate units, and they must transfer data to and from each other one bit at a time via serial buses. This struggle to move data through a congested bus is often referred to as the von Neumann bottleneck. In large software-based neural networks, roughly 90% of the training time is devoted purely to moving data around; actual computation only takes about 10% of the total time [1].
There is a type of hardware architecture that overcomes this problem. In neuromorphic computing, the massive efficiency and elegance of neurological architectures are used as inspiration. An important characteristic of neuromorphic architectures is that memory and computation reside in the same unit, making processing more efficient. However, these architectures are subject to their own set of constraints. In most neuromorphic processors, input neurons are lined up along one side of the chip, output neurons are lined up along an adjacent side, and each input neuron is connected to every output neuron. This is called a fully connected crossbar array (see Fig. 1).
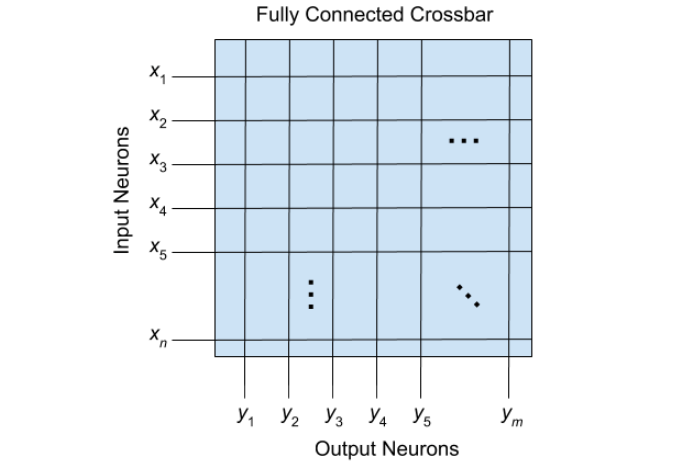
Fig. 1. A fully connected crossbar array with n input neurons and m output neurons; each input neuron is connected to every output neuron. Credit: Ross D. Pantone
These crossbar arrays scale poorly, since the chip size scales quadratically with each additional neuron — that is, the neuron density decreases as neurons are added. There have been attempts to concatenate many of these crossbar arrays into a larger architecture as a means of achieving a greater neuron density. These are often called network-on-chip architectures (see Fig. 2).
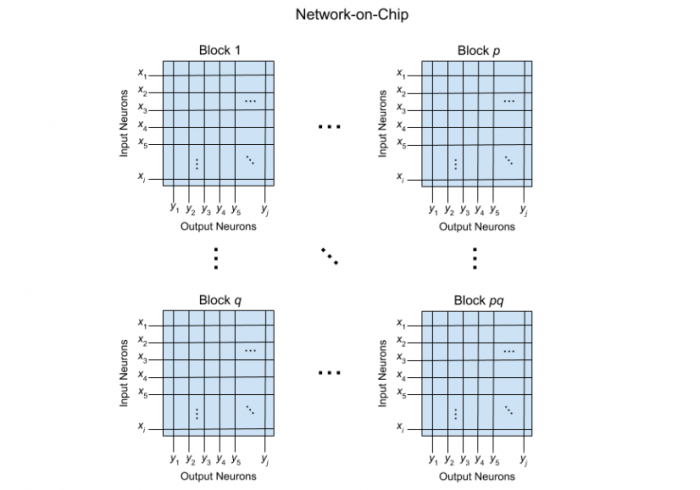
Fig. 2. A conventional network-on-chip architecture consisting of pq fully connected crossbar arrays linked together by a serial bussing system. Credit: Ross D. Pantone
However, the interconnection method used between the crossbar arrays is identical to that of the interconnection between memory and compute in GPUs. This type of architecture now faces the same problem that drove us to use neuromorphic hardware in the first place. The resulting architecture is locally parallel but globally serial, which, again, diverges greatly from neurological structures.
The human brain has approximately 1011 neurons and 1014 synapses. If it were fully connected, it would have roughly 1022 synapses. Assuming 10 nm fabrication, a fully connected chip with 1011 neurons would have to be the size of 187 football fields. In order to scale to billions of neurons, the brain uses an intelligent form of sparsity that also allows for global parallelism.
In network theory, there is a class of networks called small-world networks. In a small-world network, the nodes are not densely connected, but the minimum number of steps between two arbitrary nodes still remains small. This is the principle that underlies the idea of six degrees of separation, which states that any person in the world can be connected to any other person by a chain of no more than six acquaintances. Other examples of small-world networks include electrical power grids, protein networks, and, importantly, the neuron-synapse connectivity in the brain. This means these networks can be very well-connected without needing to be fully connected. When compared to fully connected networks, small-world networks can decrease both training time and testing error [2], [3]. None of the aforementioned computing architectures possess this mathematical classification.
Rain Neuromorphics has developed a novel neuromorphic chip architecture that forms a small-world network. This architecture overcomes the von Neumann bottleneck of GPUs and the scaling constraints of other neuromorphic chips. Rain’s Memristive Nanowire Neural Network (MN3) is composed of core-shell nanowires laid atop a grid of artificial neurons that are tiled across the entire chip, rather than just along the periphery (see Fig. 3). Each nanowire consists of a metal core to conduct signals and a memristive shell to form tunable synapses. The dense nanowire layer connects the synapses to the neurons.
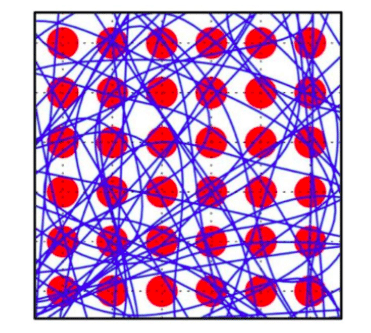
Fig. 3. An MN3 with 36 neurons (red) and 56 stochastically-deposited nanowires (blue); neurons do not need to be designated as strictly input or output. Ross D. Pantone
This allows for a massive increase in neuron density. With this architecture, the scaling issue of neuromorphic chips is resolved and linear scaling of chip size is achieved. We accomplish this by removing the neuron-synapse connectivity from the CMOS layer, which frees up a massive amount of area for neurons to be placed. We also estimate the number of neurons in the architecture to be 4,000,000 neurons per cm2 [4], which is several orders of magnitude greater than state-of-the-art values reported in the literature (see Fig. 4).
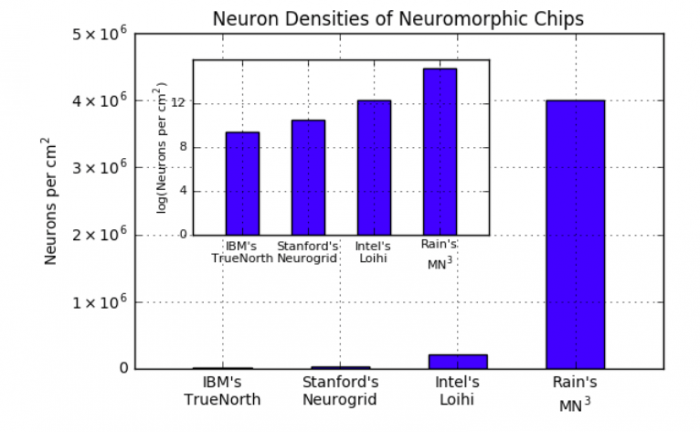
Fig. 4. A graph of neuron densities for various neuromorphic chips [5], [6], [7]; note that these three scale poorly as they possess communication bottlenecks. Credit: Ross D. Pantone
If you are interested in learning more about our technology, feel free to reach out to the author at [email protected].
These findings are described in the article entitled Memristive Nanowires Exhibit Small-World Connectivity, recently published in the journal Neural Networks. This work was conducted by Ross D. Pantone and Jack D. Kendall from Rain Neuromorphics, Inc., and Juan C. Nino from the University of Florida.
References:
- Salmon, L. (2017). 3 Dimensional Monolithic System on a Chip (3DSoC). Retrieved August 26, 2018, from https://www.darpa.mil/attachments/3DSoCProposersDay20170915.pdf.
- Li, X., Xu, F., Zhang, J., & Wang, S. (2013). A Multilayer Feed Forward Small-World Neural Network Controller and Its Application on Electrohydraulic Actuation System. Journal of Applied Mathematics.
- Erkaymaz, O., Ozer, M., Perc, M. (2017). Performance of Small-World Feedforward Neural Networks for the Diagnosis of Diabetes. Applied Mathematics and Computation, 311, 22-28.
- Pantone, R. D., Kendall J. D., & Nino, J. C. (2018). Memristive Nanowires Exhibit Small-World Connectivity. Neural Networks.
- Davies, Mike, et al. (2018). Loihi: A Neuromorphic Manycore Processor with On-chip Learning. IEEE Micro, 38, 82-99.
- Merolla, Paul A., et al. (2014). A Million Spiking-neuron Integrated Circuit with a Scalable Communication Network and Interface. Science, 345, 668-673.
- Benjamin, B. V., et al. (2014). Neurogrid: A Mixed-analog-digital Multichip System for Large-scale Neural Simulations. Proceedings of the IEEE, 102(5), 699-716.
Related Posts
 Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun
Improving Tools For Quality Improvement: Crossings, Runs, And Crossrun Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light
Coherent Poly Propagation Materials With 3-Dimensional Photonic Control Over Visible Light Reconstructing Commuter Networks Using Machine Learning And Urban Indicators
Reconstructing Commuter Networks Using Machine Learning And Urban Indicators Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread
Surprising Internal Structure Of Whole Wheat-Green Gram Functional Bread Tailoring Tomatoes To Match Individual Consumer Needs
Tailoring Tomatoes To Match Individual Consumer Needs Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms
Eavesdropping On “Classroom Talk” In Undergraduate STEM Classrooms