




Nucleotides are chemical compounds that form the basic structure of nucleic acids like RNA and DNA. The chemical structure of nucleotides is almost the same regardless of whether or not the nucleotide is an RNA or DNA nucleotide. Nucleotides are made out of elements like nitrogen and carbon with a nitrogenous base, a five-carbon sugar component, and a group of phosphates. However, there are some important differences between RNA nucleotides and DNA nucleotides. The nitrogenous bases come in one of two different forms – they are either a pyrimidine or a purine. The five carbon sugars in the nucleotide are either a deoxyribose in the case of DNA or a ribose in case of RNA.
That’s the basic structure of a nucleotide, but it is important to place nucleotides within the context of their role in biology, to see how the nucleotides interact with one another to create RNA, DNA, and proteins. Let’s examine the composition of nucleotides as well as the role they play within cells.
The Role of Nucleotides
Nucleotides are molecules which serve as the building blocks, or monomer units, for the creation of important polymers like ribonucleic acid or RNA and deoxyribonucleic acid or DNA. As mentioned, nucleotides have three component parts: a five-sided carbon sugar, a nitrogen-containing base, and a phosphate group.
The sugar and phosphate group together to create the sugar phosphate backbone. This is skeleton or foundation of the DNA double helix. The nitrogenous bases are located in the middle of the two sides of the backbone of DNA. The sugar phosphate backbone is held together by the chemical bonds formed between the sugars of one nucleotide and the phosphate group of another nuclear died. The two strands of the double helix are linked together by hydrogen bonds which are located in-between the nitrogenous bases.
Nitrogenous Bases
In terms of the nitrogenous bases, the bases are different depending on whether or not the nucleotide is RNA or DNA. DNA has four different bases called adenine, guanine, cytosine, and thymine. The nitrogenous bases in DNA are what stores genetic information, and they are also responsible for encoding phenotypes, the visible traits of the genetic code. Guanine and adenine are both purine bases, and their structure is a six sided ring combined with a five sided structure.
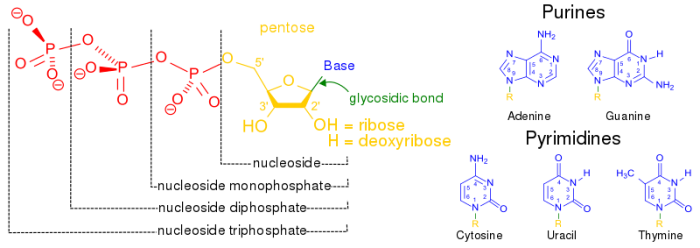
Structure of purines and pyrimidines. Photo: Boris via Wikimedia Commons, Public Domain
By contrast, thymine and cytosine are pyrimidines, and their structure is a single six-sided ring. Cytosine and guanine always bind to each other, while thymine will always bond with adenine. This system is dubbed complementary base pairing, and the bases are held together by hydrogen bonds. These hydrogen bonds can be broken apart when it is time for the DNA to replicate. The DNA essentially unzips, has the genetic information it carries read, and then reverts back to the double helix form.
Ribose And The Difference Between RNA And DNA
While the five-carbon sugar that DNA possesses is called deoxyribose, the five carbon sugar RNA possesses is just called ribose. Ribose is necessary for the formation of molecules utilized to transfer energy between different portions of a cell. It also functions as part of the scaffolding for the creation of chromosomes. Beyond the fact that RNA and DNA have different five-carbon sugars, there are other differences as well. RNA and DNA have different pyrimidine bases. DNA has thymine and cytosine as it pyrimidine bases, while RNA has cytosine and a different substance called uracil as its pyrimidine basis.
The structure of DNA and RNA is also different. DNA is known for its double helix structure. The double helix is two strands that are intertwined with one another thanks to the complementary bases. RNA is a single-stranded molecule by contrast. The double helix form of DNA helps keep the genetic code intact. If one strand is damaged, the other strand merely has to bond with the complementary base to repair itself.
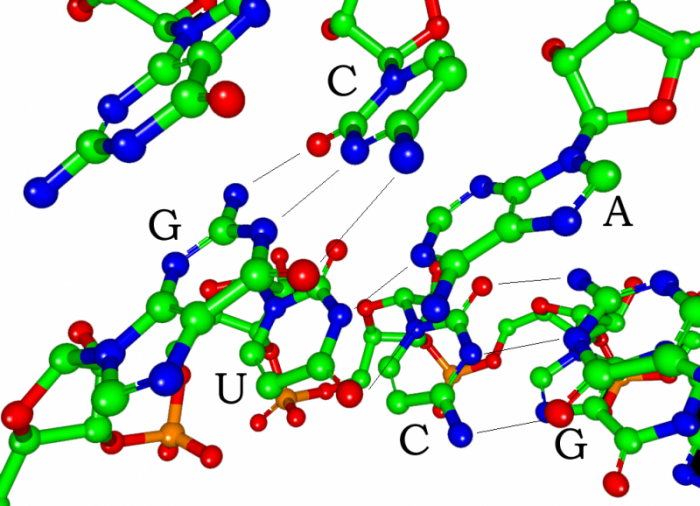
Photo: By Narayanese, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=3491727
Furthermore, while there is only one form of DNA, there are multiple types of RNA. The three primary types of RNA are transfer RNA (tRNA), ribosomal RNA (rRNA), and messenger RNA (mRNA). Messenger RNA carries genetic information to the ribosomes from the DNA, allowing the correct proteins to be synthesized. Ribosomal RNA, as the name implies, is involved in the creation of ribosomes, and it comprises around 60% of the mass of ribosomes. This form of RNA is needed to properly align the mRNA and give the mRNA a point of attachment. Transfer RNA brings the requisite amino acids to the ribosomes so that they can be used to synthesized proteins.
While DNA can store more genetic information than RNA can, DNA could not accomplish its job of replication without the assistance of RNA. Some scientists theorize that RNA may have evolved before DNA. The simpler structure of RNA, and the fact that DNA relies on RNA to function implies that RNA may have been the progenitor of the system of replication that cells now depend on. Furthermore, prokaryotic cells possess RNA, and they are typically believed to have evolved prior to eukaryotic cells.
Difference Between Nucleosides And Nucleotides
Nucleotides should not be confused with the similar sounding molecule nucleosides. What’s the difference between the two molecules? Essentially, nucleosides are molecules which are similar in structure to nucleotides, except that they lack the phosphate group that nucleotides have. Nucleosides become nucleotides through the process of phosphorylation. Phosphorylation is when phosphorus and nucleosides combine together to create a nitrogenous base with phosphate and sugar.
Nucleosides can be created of cells of the body through the process of the synthesis, but nucleosides can also be acquired by ingesting food. The nucleotides present in food are broken down into phosphate and nucleosides, pulled apart by an enzyme called nucleotidase.
Protein Synthesis And Codons
Strands of RNA created for the purpose of protein synthesis have three letter long codes that specify certain aspects and features of the protein. These three letter codes are called codons, and they are comprised of any combination of RNA’s four nucleotide bases. Codons are one of the factors responsible for ensuring the proper synthesis of a given protein. Protein synthesis begins as the mRNA arrives at the site of the ribosome. The ribosome is the structure that will produce the proteins, but it needs to have the proper information or blueprints to do so. The mRNA has the genetic sequences for these proteins, and the ribosome reads the instructions to create the proteins.
In general, the start of protein synthesis is kicked off by the reading of the codon AUG or methionine. This is a start codon specifying the beginning of the protein chain. When the ribosome reads this start codon, transfer RNA is brought into the ribosome as well. This transfer RNA has the necessary amino acids and an anti-codon, or the complementary sequence to the codon specified by the messenger RNA. The complementary sequence for AUG is UAC.
For proteins to be produced, the mRNA codons have to match the anti-codon provided by the tRNA. If a match is found, the ribosome brings in the next bit of genetic information from another tRNA and matches it with the next codon provided by the mRNA. If this is also a match, amino acids on the new tRNA strand are bonded with the previous amino acids and the ribosomes then move on to the next codon in the sequence.
This same process will go on until the ribosome finds the codon to specify the end of that sequence, the stop codon. The stop codon on a strand of mRNA can be UGA, UAG, or UAA. Once this stop codon is found the protein-encoding process is finished. There are 64 codons in total. One is the start codon and three of them are stop codons, so there are 61 codons which can be combined in different ways. Humans create amino acids with only 20 different codons, as do other organisms, so humans have many redundancies within the codon chain. As an example, the codons UUG and UUA are both capable of encoding for the protein leucine. Meanwhile, the protein proline is encoded for by CCA, CCC, and CCU.
One of the reasons that there are multiple codons which code for the same protein is because this helps defend the genetic sequence against mutations and the ensuing problems that could occur if protein synthesis was disrupted. While some mutations can be beneficial, many mutations cause various genetic disorders and cancers or put us at greater risk for various diseases. The fact that multiple codons code for the same proteins helps minimize the risks of developing harmful mutations.
There are also mutations referred to as silent mutations because even though there are changes to the DNA sequence, the particular protein that is produced ends up being the same. These silent mutations (also referred to as anonymous substitutions) are found in situations like the production of the protein leucine. While the DNA sequence CTT would normally code for leucine, a mutation that changes the sequence to CTC might occur. However, this particular mutation would still produce leucine, and thus it is a silent mutation.
Related Posts
 Important Strategies To Help Healthcare Providers Support Patients With Diabetes
Important Strategies To Help Healthcare Providers Support Patients With Diabetes Studying The Link Between Increased BMI And Late-Onset Preeclampsia In Pregnant Women
Studying The Link Between Increased BMI And Late-Onset Preeclampsia In Pregnant Women A Bacterial Cell Imaging Method Using CRISPR And Microfluidics
A Bacterial Cell Imaging Method Using CRISPR And Microfluidics B. infantis Reduces Key Markers Of Intestinal Inflammation In Infants
B. infantis Reduces Key Markers Of Intestinal Inflammation In Infants Epigenetic Changes In Multiple Sclerosis – Studied In Twins
Epigenetic Changes In Multiple Sclerosis – Studied In Twins Did You Know Math Can Help Us Learn How Diseases Work?
Did You Know Math Can Help Us Learn How Diseases Work?